Section: New Results
Analysis
Forest point processes for line-network extraction
Participants : Alena Schmidt, Florent Lafarge.
In collaboration with Claus Brenner, Franz Rottensteiner and Christian Heipke from the Leibniz Universitat Hannover, Germany.
We contributed a new stochastic approach for the automatic detection of network structures in raster data. We represent a network as a set of trees with acyclic planar graphs. We embed this model in the probabilistic framework of spatial point processes and determine the most probable configuration of trees by stochastic sampling. That is, different configurations are constructed randomly by modifying the graph parameters and by adding or removing nodes and edges to or from the current trees. Each configuration is evaluated based on the probabilities for these changes and an energy function describing the conformity with a predefined model. Although our main target application is the extraction of rivers and tidal channels in digital terrain models as illustrated on Figure 1, experiments with other types of networks in images show the transferability to further applications. Qualitative and quantitative evaluations demonstrate the competitiveness of our approach with respect to existing algorithms. This work was published in the ISPRS journal [21].
|
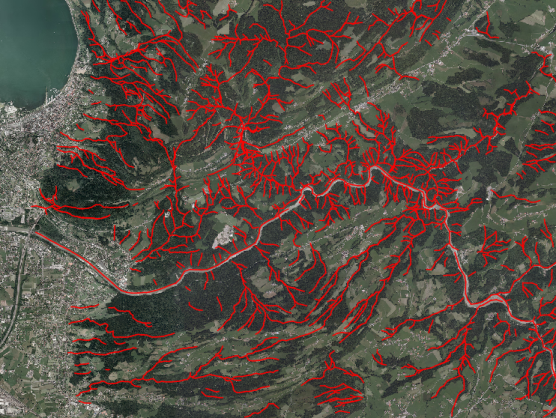
Photo2ClipArt: Image Abstraction and Vectorization Using Layered Linear Gradients
Participants : Jean-Dominique Favreau, Florent Lafarge.
In collaboration with Adrien Bousseau (GraphDeco Inria team)
We proposed a method to create vector cliparts from photographs. Our approach aims at reproducing two key properties of cliparts: they should be easily editable, and they should represent image content in a clean, simplified way. We observe that vector artists satisfy both of these properties by modeling cliparts with linear color gradients, which have a small number of parameters and approximate well smooth color variations. In addition, skilled artists produce intricate yet editable artworks by stacking multiple gradients using opaque and semi-transparent layers. Motivated by these observations, our goal is to decompose a bitmap photograph into a stack of layers, each layer containing a vector path filled with a linear color gradient. We cast this problem as an optimization that jointly assigns each pixel to one or more layer and finds the gradient parameters of each layer that best reproduce the input. Since a trivial solution would consist in assigning each pixel to a different, opaque layer, we complement our objective with a simplicity term that favors decompositions made of few, semi-transparent layers. However, this formulation results in a complex combinatorial problem combining discrete unknowns (the pixel assignments) and continuous unknowns (the layer parameters). We propose a Monte Carlo Tree Search algorithm that efficiently explores this solution space by leveraging layering cues at image junctions. We demonstrate the effectiveness of our method by reverse-engineering existing cliparts and by creating original cliparts from studio photography (see Figure 2). This work was published at ACM SIGGRAPH ASIA and in ACM Transactions on Graphics 2017 [14].
|

Semantic segmentation of 3D textured meshes
Participants : Florent Lafarge, Pierre Alliez.
In collaboration with Mohammad Rouhani, now at Technicolor, France.
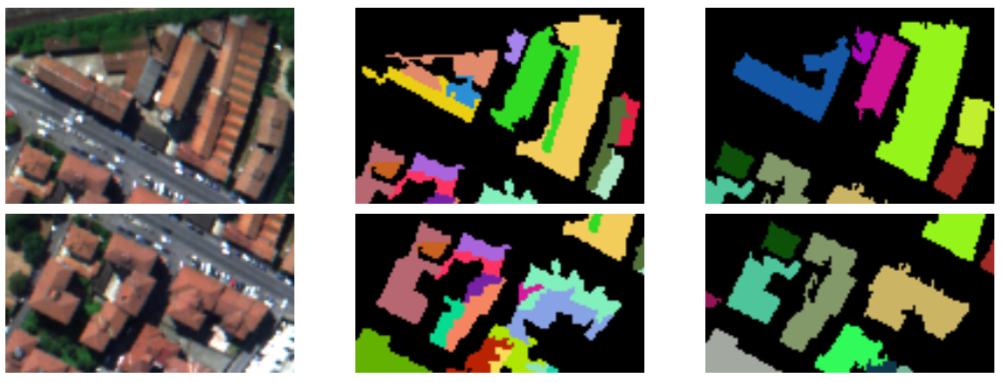
Classifying 3D measurement data has become a core problem in photogrammetry and 3D computer vision, since the rise of modern multiview geometry techniques, combined with affordable range sensors. We introduce a Markov Random Field-based approach for segmenting textured meshes generated via multi-view stereo into urban classes of interest. The input mesh is first partitioned into small clusters, referred to as superfacets, from which geometric and photometric features are computed. A random forest is then trained to predict the class of each superfacet as well as its similarity with the neighboring superfacets. Similarity is used to assign the weights of the Markov Random Field pairwise-potential and accounts for contextual information between the classes. The experimental results illustrate the efficacy and accuracy of the proposed framework (See Figure 3). This work was published in the ISPRS journal [20].
|
Convolutional Neural Networks for Large-Scale Remote-Sensing Image Classification
Participants : Emmanuel Maggiori, Yuliya Tarabalka, Pierre Alliez.
In collaboration with Guillaume Charpiat (Inria TAO team).
We propose an end-to-end framework for the dense, pixelwise classification of satellite imagery with convolutional neural networks (CNNs). In our framework, CNNs are directly trained to produce classification maps out of the input images. We first devise a fully convolutional architecture and demonstrate its relevance to the dense classification problem. We then address the issue of imperfect training data through a two-step training approach: CNNs are first initialized by using a large amount of possibly inaccurate reference data, then refined on a small amount of accurately labeled data. To complete our framework we design a multi-scale neuron module that alleviates the common trade-off between recognition and precise localization. A series of experiments show that our networks take into account a large amount of context to provide fine-grained classification maps (Figure 4). This work was published in IEEE Transactions on Geoscience and Remote Sensing (TGRS) [17].
|

High-Resolution Semantic Labeling with Convolutional Neural Networks
Participants : Emmanuel Maggiori, Yuliya Tarabalka, Pierre Alliez.
In collaboration with Guillaume Charpiat (Inria TAO team)
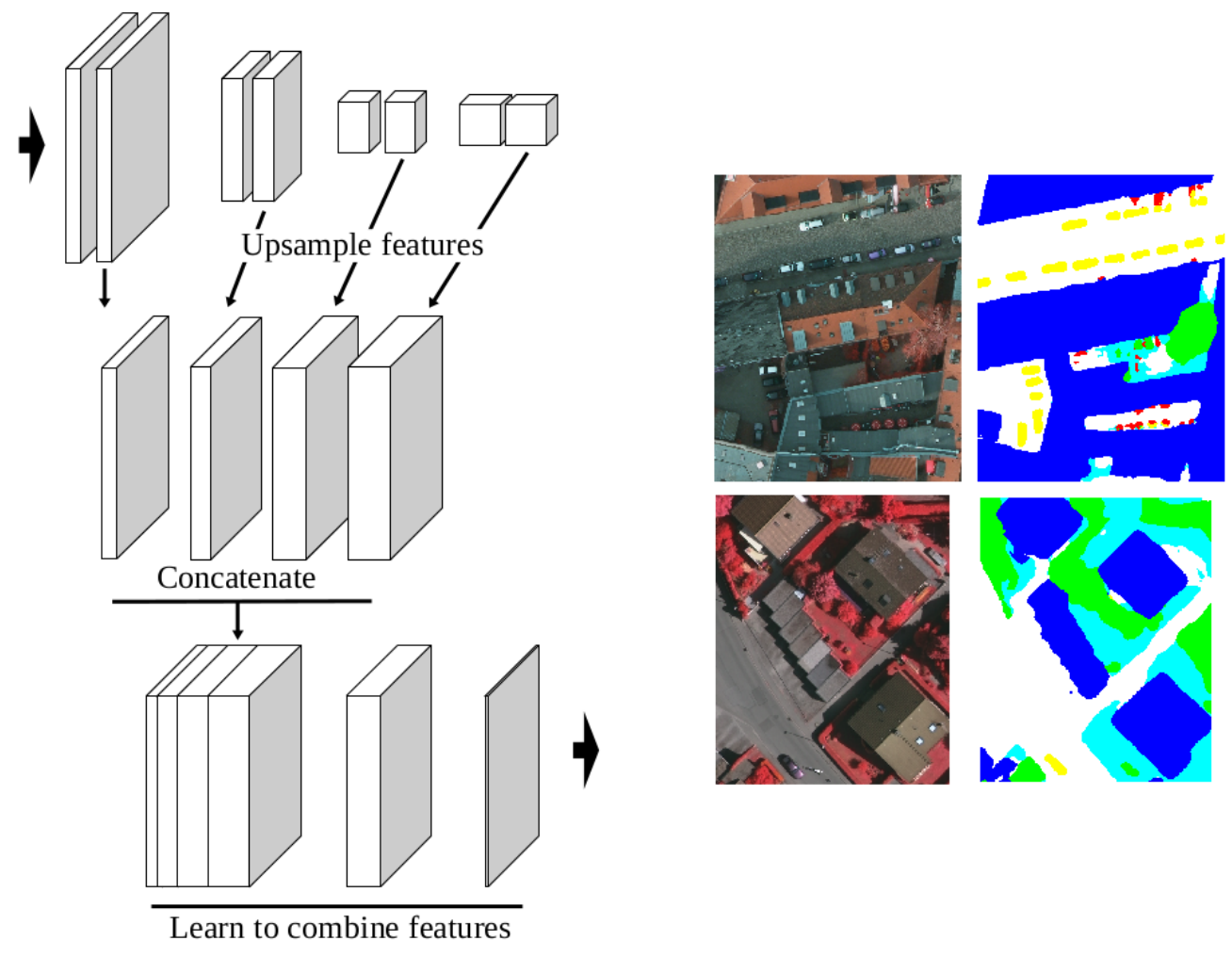
Convolutional neural networks (CNNs) were initially conceived for image categorization, i.e., the problem of assigning a semantic label to an entire input image. We have address the problem of dense semantic labeling, which consists in assigning a semantic label to every pixel in an image. Since this requires a high spatial accuracy to determine where labels are assigned, categorization CNNs, intended to be highly robust to local deformations, are not directly applicable. By adapting categorization networks, many semantic labeling CNNs have been recently proposed. Our first contribution is an in-depth analysis of these architectures. We establish the desired properties of an ideal semantic labeling CNN, and assess how those methods stand with regard to these properties. We observe that even though they provide competitive results, these CNNs often do not leverage properties of semantic labeling that could lead to more effective and efficient architectures. Out of these observations, we then derive a CNN framework specifically adapted to the semantic labeling problem [23], [18]. In addition to learning features at different resolutions, it learns how to combine these features (Figure 5). By integrating local and global information in an efficient and flexible manner, it outperforms previous techniques. We evaluate the proposed framework and compare it with state-of-the-art architectures on public benchmarks of high-resolution aerial image labeling. This work was published in IEEE Transactions on Geoscience and Remote Sensing and was presented at the IEEE International Geoscience and Remote Sensing Symposium (IGARSS).
|
Learning Iterative Processes with Recurrent Neural Networks to Correct Satellite Image Classification Maps
Participants : Emmanuel Maggiori, Yuliya Tarabalka, Pierre Alliez.
In collaboration with Guillaume Charpiat (Inria TAO team)
While initially devised for image categorization, convolutional neural networks (CNNs) are being increasingly used for the pixelwise semantic labeling of images. However, the proper nature of the most common CNN architectures makes them good at recognizing but poor at localizing objects precisely. This problem is magnified in the context of aerial and satellite image labeling, where a spatially fine object outlining is of paramount importance.
Different iterative enhancement algorithms have been presented in the literature to progressively improve the coarse CNN outputs, seeking to sharpen object boundaries around real image edges. However, one must carefully design, choose and tune such algorithms. Instead, our goal is to directly learn the iterative process itself. For this, we formulate a generic iterative enhancement process inspired from partial differential equations, and observe that it can be expressed as a recurrent neural network (RNN). Consequently, we train such a network from manually labeled data for our enhancement task. In a series of experiments we show that our RNN effectively learns an iterative process that significantly improves the quality of satellite image classification maps (Figure 6). This work was published in IEEE Transactions on Geoscience and Remote Sensing [16].
|

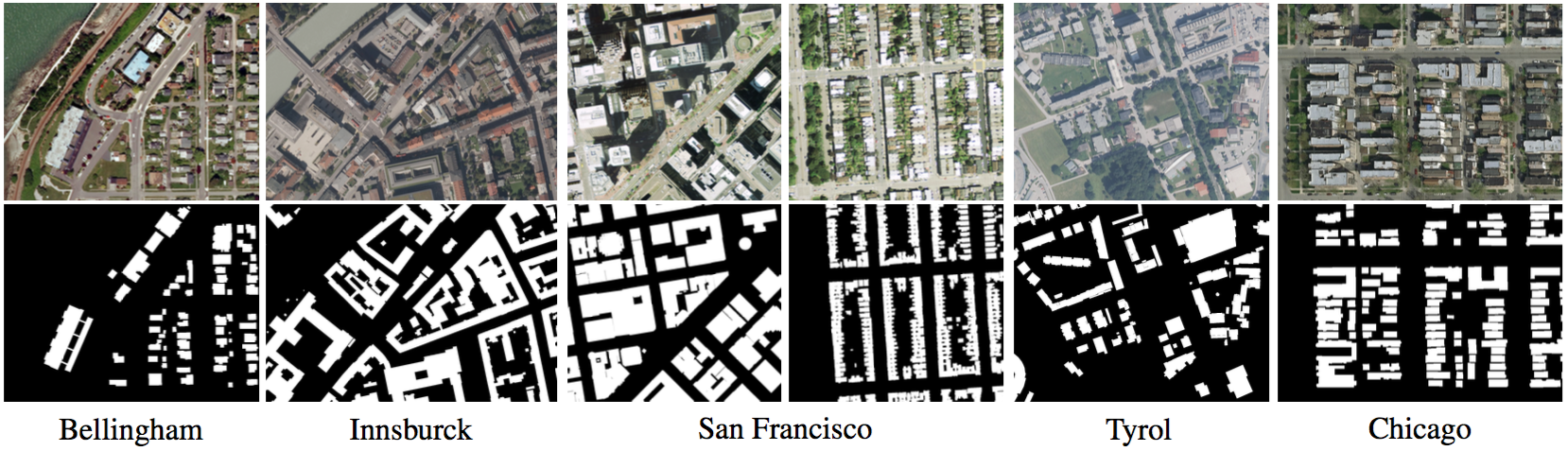
Can semantic labeling methods generalize to any city? The Inria Aerial Image Labeling Benchmark
Participants : Emmanuel Maggiori, Yuliya Tarabalka, Pierre Alliez.
In collaboration with Guillaume Charpiat (Inria TAO team)
New challenges in remote sensing impose the necessity of designing pixel classification methods that, once trained on a certain dataset, generalize to other areas of the earth. This may include regions where the appearance of the same type of objects is significantly different. In the literature it is common to use a single image and split it into training and test sets to train a classifier and assess its performance, respectively. However, this does not prove the generalization capabilities to other inputs. In this work, we propose an aerial image labeling dataset that covers a wide range of urban settlement appearances, from different geographic locations (see Fig. 7). Moreover, the cities included in the test set are different from those of the training set. We also experiment with convolutional neural networks on our dataset. This work was presented at the IEEE International Symposium on Geoscience and Remote Sensing (IGARSS) [22].
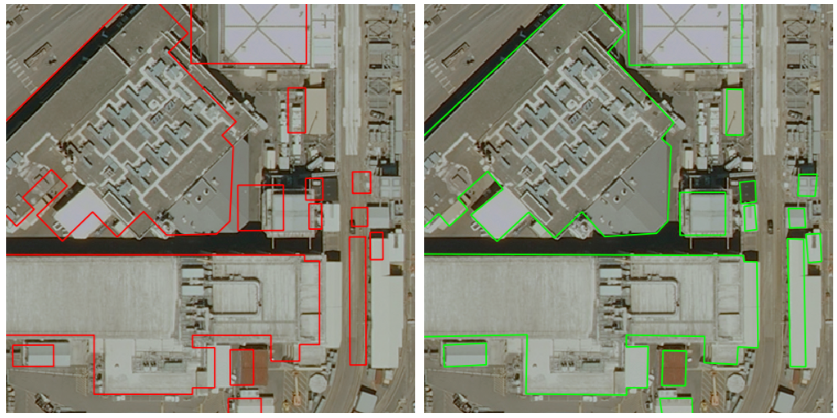
Coarse to fine non-rigid registration: a chain of scale-specific neural networks for multimodal image alignment with application to remote sensing
Participants : Armand Zampieri, Yuliya Tarabalka.
In collaboration with Guillaume Charpiat (Inria TAO team)
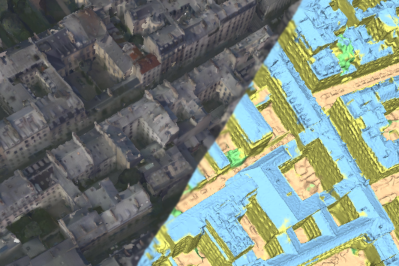
We tackle here the problem of multimodal image non-rigid registration, which is of prime importance in remote sensing and medical imaging. The difficulties encountered by classical registration approaches include feature design and slow optimization by gradient descent. By analyzing these methods, we note the significance of the notion of scale. We design easy-to-train, fully-convolutional neural networks able to learn scale-specific features. Once chained appropriately, they perform global registration in linear time, getting rid of gradient descent schemes by predicting directly the deformation. We show their performance in terms of quality and speed through various tasks of remote sensing multimodal image alignment. In particular, we are able to register correctly cadastral maps of buildings (see Fig. 8) as well as road polylines onto RGB images, and outperform current keypoint matching methods.
|
Models for hyperspectral image analysis: from unmixing to object-based classification
Participants : Emmanuel Maggiori, Yuliya Tarabalka.
In collaboration with Antonio Plaza (University of Extremadura)
The recent advances in hyperspectral remote sensing technology allow the simultaneous acquisition of hundreds of spectral wavelengths for each image pixel. This rich spectral information of the hyperspectral data makes it possible to discriminate different physical substances, leading to a potentially more accurate classification (see example classifications Figure 9) and thus opening the door to numerous new applications. Throughout the history of remote sensing research, numerous methods for hyperspectral image analysis have been presented. Depending on the spatial resolution of the images, specific mathematical models must be designed to effectively analyze the imagery. Some of these models operate at a sub-pixel level, trying to decompose a mixed spectral signature into its pure constituents, while others operate at a pixel or even object level, seeking to assign unique labels to every pixel or object in the scene. The spectral mixing of the measurements and the high dimensionality of the data are some of the challenging features of hyperspectral imagery. This work presents an overview of unmixing and classification methods, intended to address these challenges for accurate hyperspectral data analysis. This work was published as a book chapter [26].